力扣690题:哈希表+BFS解决员工的重要性
2个月前 (08-25)

一、题目解读
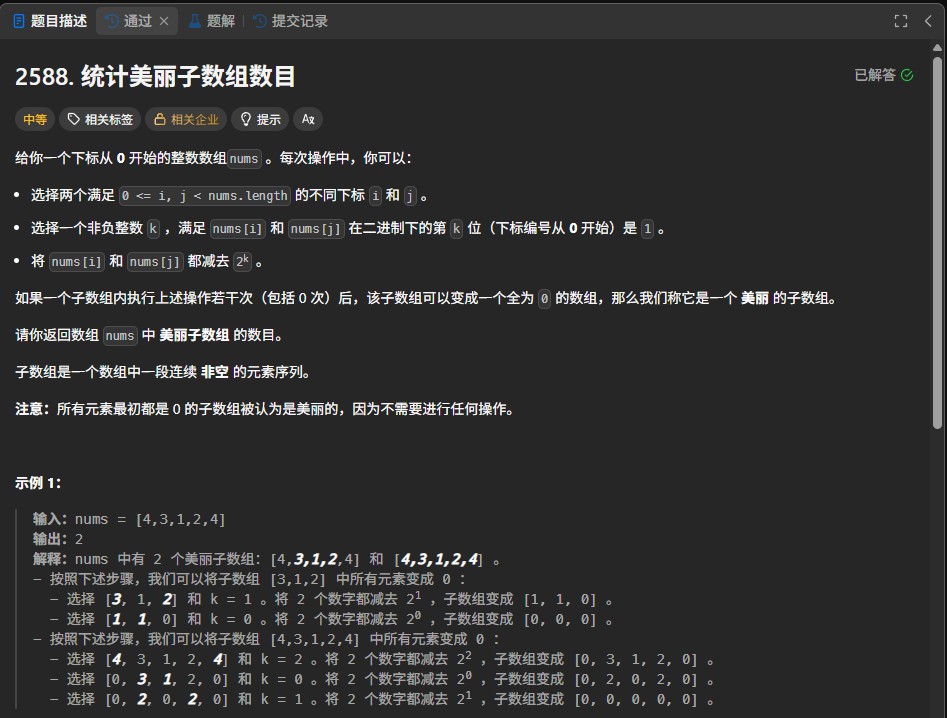
LeetCode第690题“员工的重要性”要求给定一个员工信息数组(包含id、重要性值及下属id列表),计算指定id员工及其所有下属的总重要性。题目核心在于处理树状结构数据,需遍历员工关系并累加重要性,同时考虑高效查找与遍历策略。
二、解题思路
1. 哈希表映射:将员工信息存储于unordered_map,通过id直接O(1)查找员工对象,避免线性遍历。
2. 广度优先搜索(BFS):从目标员工开始,逐层遍历其下属,累加重要性值,确保不遗漏任何层级。
该解法兼具时间效率(O(n))与代码简洁性,适用于树状数据的广度优先处理场景。
三、解题步骤
1. 创建哈希表:遍历员工数组,将每个员工的id映射至其对象,构建emp_map。
2. 初始化队列:将目标id加入队列q,作为BFS起点。
3. BFS循环:
弹出队首元素current_id,获取对应员工对象。
累加其重要性至total_importance。
将其所有下属id加入队列,扩展遍历范围。
4. 终止条件:队列为空时,所有员工已遍历完毕。
5. 返回结果:total_importance为最终总重要性。
四、代码与注释
class Solution {
public:
int getImportance(vector<Employee*> employees, int id) {
// 创建哈希表快速查找员工
unordered_map<int, Employee*> emp_map;
for (auto emp : employees) {
emp_map[emp->id] = emp;
}
// 使用队列进行广度优先搜索(BFS)
queue<int> q;
q.push(id);
int total_importance = 0;
while (!q.empty()) {
int current_id = q.front();
q.pop();
// 获取当前员工对象
Employee* current_emp = emp_map[current_id];
// 累加重要度
total_importance += current_emp->importance;
// 将下属加入队列
for (int sub_id : current_emp->subordinates) {
q.push(sub_id);
}
}
return total_importance;
}
};五、总结
该解法巧妙结合哈希表的快速查找与BFS的广度遍历,将树状数据处理转化为线性操作,显著优化时间复杂度。核心启示:对于涉及多层关系的数据结构,预先构建索引(如哈希表)并采用广度优先策略,可大幅提升算法效率。对解决树/图类算法问题具有通用参考价值。
原创内容 转载请注明出处