手搓双向链表代码全解析:从零开始实现双向链表数据结构(附注释与实战步骤)
一、简介和特点
双向链表(Double Linked List)是一种基础的数据结构,它由多个节点组成,每个节点包含数据域、指向下一个节点的指针(next)和指向前一个节点的指针(last)。与单向链表相比,双向链表允许从任意节点向前或向后遍历,因此在需要频繁插入、删除或双向遍历的场景中具有优势。本文将通过您手写的双向链表代码,详细解析其实现原理与操作步骤。
二、与其他数据结构的优点对比
1. 对比单向链表:单向链表只能单向遍历,删除或插入时需要先找到前驱节点,而双向链表通过last指针可直接定位前驱,操作效率更高。
2. 对比数组:双向链表插入和删除元素时不需要移动大量数据,时间复杂度为O(1)(找到位置后),而数组在插入或删除中间元素时需要移动后续元素,时间复杂度为O(n)。
3. 灵活性:动态分配内存,无需提前确定容量,适合数据量动态变化的场景。
三、实现步骤
1. 定义节点结构:包含数据(data)、指向下一个节点(next)和指向前一个节点(last)的指针。
2. 初始化链表头节点:head指向头节点,头节点不存储数据,仅作为链表起始标志。
3. 添加节点(add方法):从head开始遍历至末尾,创建新节点并插入到末尾,连接next和last指针。
4. 插入节点(insert方法):根据索引idx找到目标位置,调整前后节点的指针关系,插入新节点。
5. 删除节点(delnode方法):根据索引找到目标节点,断开其前后节点的指针连接,释放内存。
6. 修改节点数据(change方法):定位到索引对应的节点,直接修改data值。
7. 选择节点数据(select方法):根据索引返回对应节点的数据。
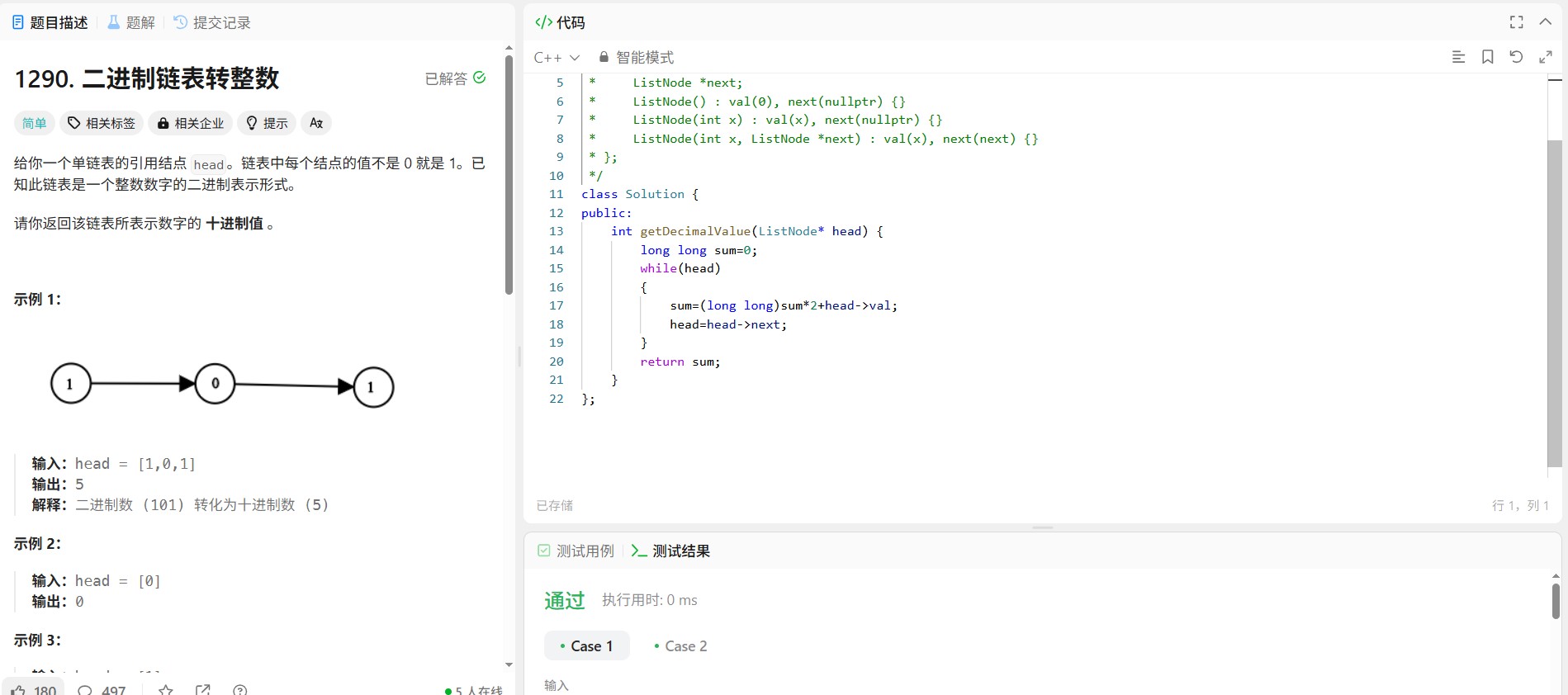
四、代码及注释
#include <iostream>
using namespace std;
// 节点结构定义
struct node {
int data = 0; // 数据域(默认初始化为0)
node* next = nullptr; // 指向下一个节点的指针
node* last = nullptr; // 指向前一个节点的指针
};
class linklist {
node* head = new node; // 头节点,不存储数据,仅作为链表入口
public:
// 1. 添加节点到链表末尾
void add(int data) {
node* tmp = head; // 临时指针从head开始遍历
while (tmp->next!= nullptr) { // 遍历至末尾节点
tmp = tmp->next;
}
node* datanode = new node; // 创建新节点
datanode->data = data; // 赋值数据
tmp->next = datanode; // 末尾节点的next指向新节点
datanode->last = tmp; // 新节点的last指向末尾节点
}
// 2. 在指定索引位置插入节点
void insert(int data, int idx) {
node* tmp = head; // 从head开始遍历
for (int i = 0; i < idx; i++) { // 定位到目标位置的前一个节点
tmp = tmp->next;
}
node* datanode = new node; // 创建新节点
datanode->data = data;
// 调整指针关系:
// (1) 新节点的last指向当前节点的前一个节点
datanode->last = tmp->next->last;
// (2) 新节点的next指向当前节点的下一个节点
datanode->next = tmp->next;
// (3) 当前节点的next指向新节点
tmp->next = datanode;
// (4) 原下一个节点的last指向新节点
datanode->next->last = datanode;
}
// 3. 删除指定索引的节点
void delnode(int idx) {
node* tmp = head; // 从head开始遍历
for (int i = 0; i < idx; i++) { // 定位到目标节点
tmp = tmp->next;
}
// 跳过目标节点,连接前后节点:
// (1) 当前节点的next跳过目标节点
tmp->next = tmp->next->next;
// (2) 原下一个节点的last指向当前节点
tmp->next->last = tmp;
}
// 4. 修改指定索引节点的数据
void change(int data, int idx) {
node* tmp = head; // 遍历到目标节点
for (int i = 0; i <= idx; i++) {
// 注意:i <= idx(包括索引位置)
tmp = tmp->next;
}
tmp->data = data; // 直接赋值
}
// 5. 获取指定索引节点的数据
int select(int idx) {
node* tmp = head; // 遍历到目标节点
for (int i = 0; i <= idx; i++) {
tmp = tmp->next;
}
return tmp->data; // 返回数据
}
};五、总结
通过手搓双向链表代码,我们深入理解了其核心原理:利用双向指针实现灵活的数据操作,尤其在插入和删除时避免了单向链表需要查找前驱节点的开销。对于新手来说,掌握双向链表的设计思路有助于加深对指针操作和数据结构逻辑的理解。在实际开发中,双向链表常用于需要双向遍历的场景(如LRU缓存淘汰算法、双向队列等)。持续练习基础数据结构的实现,将为算法设计与优化打下坚实基础。
原创内容 转载请注明出处