力扣2842题解析:子序列计数与组合数学优化(含代码详解)
2个月前 (08-14)
 力扣题解 组合数学 动态规划 哈希表 频率统计 第1张")
一、题目解读
力扣2842题要求给定字符串s和整数k,计算s中长度为k子序列数量。返回结果对10^9+7取模。题目难点在于平衡字符频率统计与组合数学计算,避免超时。
二、解题思路
采用“频率统计+组合数计算”策略:
1. 利用哈希表(unordered_map)统计s中各字符频率,快速获取不同字符数。
2. 若不同字符数不足k,直接返回0,减少无效计算。
3. 对频率降序排序,确保优先处理高频字符,降低后续组合计算复杂度。
4. 通过滑动窗口统计相同频率字符的个数,结合组合数学公式计算重复字符的组合方案数,最终乘积取模。
三、解题步骤
1. 频率统计:遍历s,用哈希表记录每个字符的出现次数,获取不同字符数(即潜在美观度)。
2. 边界判断:若不同字符数< k,无解,直接返回0。
3. 频率排序:将频率存入vector并降序排序,便于后续组合计算。
4. 核心计算:
○ 遍历前k个频率,累乘每个频率作为子序列基数(res *= counts[i])。
○ 使用last和same_count记录当前频率的连续相同次数。
5. 处理重复频率:计算相同频率字符的总数(total_same)与组合数C(total_same, same_count),乘积并入结果。
6. 取模优化:所有乘积均对MOD取模,防止溢出。
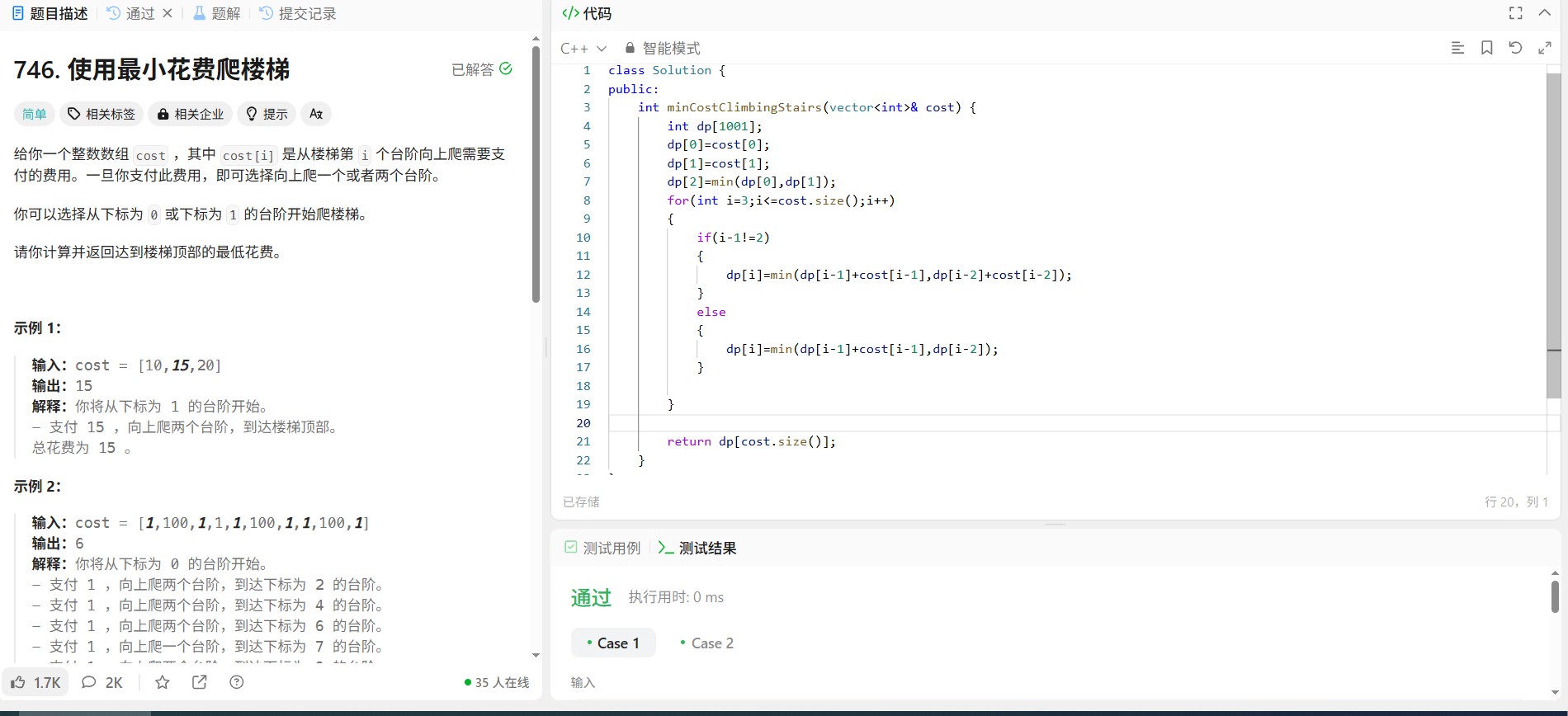
四、代码与注释
class Solution {
public:
int countKSubsequencesWithMaxBeauty(string s, int k) {
const int MOD = 1e9 + 7;
// 统计每个字符的出现频率
unordered_map<char, int> freq;
for (char c : s) {
freq[c]++;
}
// 如果不同字符数小于k,不可能有k子序列,返回0
if (freq.size() < k) {
return 0;
}
// 将频率从高到低排序
vector<int> counts;
for (auto& [c, cnt] : freq) {
counts.push_back(cnt);
}
sort(counts.rbegin(), counts.rend());
long long res = 1;
int last = -1;
int same_count = 0;
for (int i = 0; i < k; ++i) {
res = (res * counts[i]) % MOD;
// 统计有多少个字符的频率等于当前处理的频率
if (counts[i] == last) {
same_count++;
} else {
last = counts[i];
same_count = 1;
}
}
// 处理相同频率的情况
int total_same = 0;
for (int cnt : counts) {
if (cnt == last) {
total_same++;
}
}
// 计算组合数 C(total_same, same_count)
long long comb = 1;
for (int i = 1; i <= same_count; ++i) {
comb = comb * (total_same - same_count + i) / i;
}
res = (res * comb) % MOD;
return res;
}
};五、总结
本解法核心在于将子序列计数转化为频率排序与组合数学问题,通过预处理频率、降序遍历与动态统计重复次数,大幅降低计算复杂度。此外,取模操作贯穿全程,确保大数据场景下的正确性。该方案兼顾效率与可读性,是解决此类子序列计数问题的典型范式。
原创内容 转载请注明出处